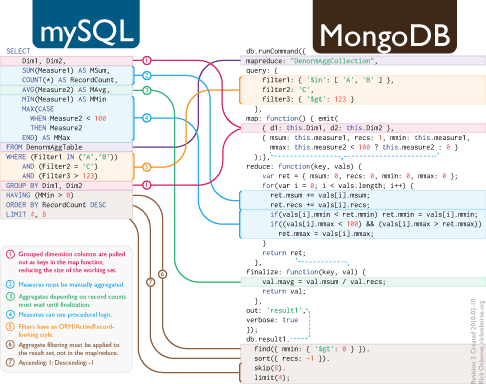
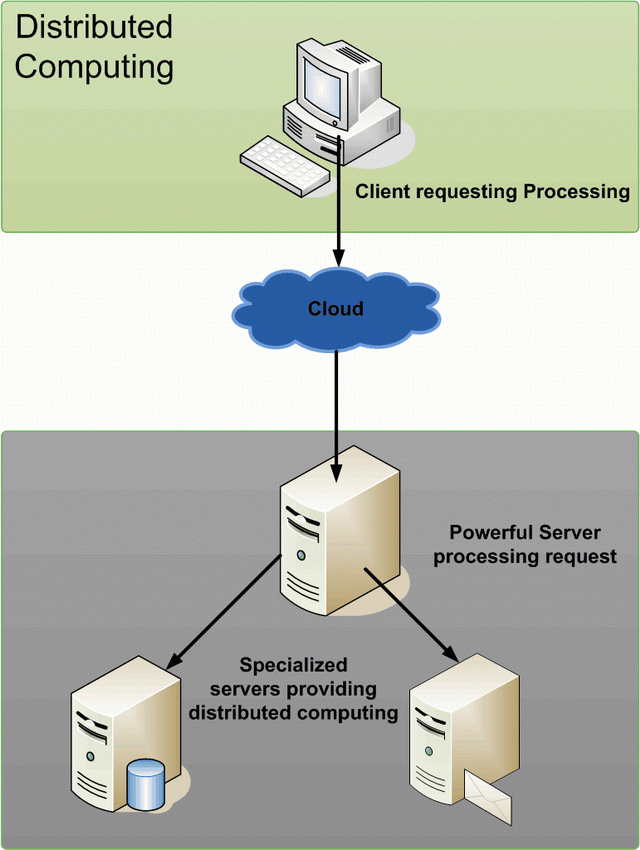
DISUSUN OLEH :
Nama : Rama Wicaksana
NIM : 11510030
Kampus : STTC (Sekolah Tinggi Teknik Cendekia)

Arsitektur
paralel komputer menurut Klasifikasi Flynn’s:
Komputer ini adalah tipe komputer konvensional, komputer ini memiliki hanya satu prosesor dan satu instruksi yang dieksekusi secara serial. Menurut mereka tipe komputer ini tidak ada dalam praktik komputer paralel karena bahkan mainframe pun tidak lagi menggunakan satu prosesor. Klasifikasi ini sekedar untuk melengkapi definisi komputer paralel.
Beberapa contoh komputer yang menggunakan model SISD yaitu seperti : UNIVAC1, IBM 360, CDC 7600, Cray 1 dan PDP 1.

Komputer ini memiliki lebih dari satu prosesor, tetapi hanya mengeksekusi satu instruksi secara paralel pada data yang berbeda pada level lock-step. Komputer vektor adalah salah satu komputer paralel yang menggunakan arsitektur ini.
Beberapa contoh komputer yang menggunakan model SIMD yaitu seperti : ILLIAC IV, MasPar, Cray X-MP, Cray Y-MP, Thingking Machine CM-2 dan Cell Processor (GPU).

Teorinya komputer ini memiliki satu prosesor dan mengeksekusi beberapa instruksi secara paralel tetapi praktiknya tidak ada komputer yang dibangun dengan arsitektur ini karena sistemnya tidak mudah dipahami. Sampai saat ini belum ada komputer yang menggunakan model MISD.

Komputer ini memiliki lebih dari satu prosesor dan mengeksekusi lebih dari satu instruksi secara paralel. Tipe komputer ini yang paling banyak digunakan untuk membangun komputer paralel, bahkan banyak supercomputer yang menerapkan arsitektur ini. Beberapa komputer yang menggunakan model MIMD yaitu seperti : IBM POWER5, HP/Compaq AlphaServer, Intel IA32, AMD Opteron, Cray XT3 dan IBM BG/L.

Sistem komputer
paralel dibedakan dari cara kerja memorinya menjadi shared memory dan
distributed memory. Shared memory berarti memori tunggal diakses oleh satu atau
lebih prosesor untuk menjalankan instruksi sedangkan distributed memory berarti
setiap prosesor memiliki memori sendiri untuk menjalankan instruksi. Adapun
komponen-komponen utama dari arsitektur komputer paralel cluster PC antara
lain:
·
Prosesor (CPU). Bagian paling penting dalam
sistem, untuk multicore terdapat lebih dari satu core yang mengakses sebuah
memori (shared memory).
·
Memori. Bagian ini dapat diperinci lagi
menjadi beberapa bagian penyusunnya seperti RAM, cache memory dan memori
eksternal.
·
Sistem Operasi. Software dasar untuk
menjalankan sistem komputer.
·
Cluster Middleware. Antarmuka antara hardware
dan software.
·
Programming Environment dan Software Tools.
Software yang digunakan untuk pemrograman paralel termasuk software
pendukungnya.
·
User Interface. Software yang menjadi
perantara hardware dengan user.
·
Aplikasi. Software berisi program
permasalahan yang akan diselesaikan.
·
Jaringan. Penghubung satu PC (prosesor)
dengan PC yang lain sehingga memungkinkan pemanfaatan sumberdaya secara
simultan.